STT 알아보기
2025-06-29
🧠 요약
- 요약: 음성 데이터를 텍스트로 변환하는 STT(Speech-to-Text) 기술은 어떻게 작동할까? 이 글은 STT의 핵심 구성 요소인 음향 모델과 언어 모델의 원리를 알아보고, 대표적인 오픈소스 모델인 OpenAI의 Whisper를 중심으로 그 구조와 기술적 특징을 탐구한다.
📌 본문
소리가 텍스트가 되기까지: STT 기술의 중요성
우리는 일상에서 음성 비서, 실시간 자막, 음성 메모 등 수많은 음성 인식 기술을 사용하고 있다. 이 모든 서비스의 근간에는 음성 데이터를 텍스트로 변환하는 STT(Speech-to-Text), 즉 자동 음성 인식(ASR) 기술이 자리 잡고 있다. 개발자에게 STT의 원리를 이해하는 것은 단순히 API를 호출하는 것을 넘어, 더 정교하고 사용자 친화적인 음성 기반 애플리케이션을 만들기 위한 첫걸음이다.
무엇을 하는 기술인가?
-
목표: 사람 음성(파형) → 문자(전사).
-
출력 형태: 실시간(부분 결과) / 배치(완료 후 일괄), 타임스탬프, 화자 분할(“누가 말했는가”), 구두점·대소문자 복원, 금칙어 마스킹 등.
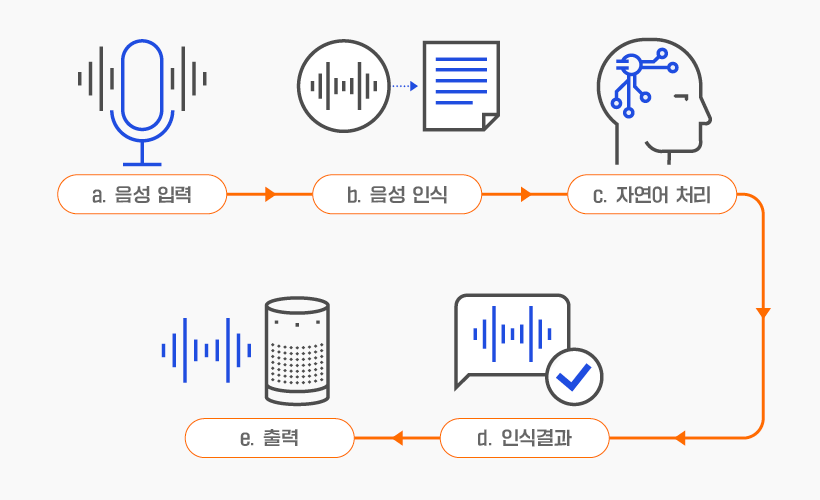 이 중 b 단계에 해당하는것이 STT 기술이다.
이 중 b 단계에 해당하는것이 STT 기술이다.
STT는 어떻게 소리를 글로 바꿀까?
STT 시스템은 크게 두 가지 핵심 모델의 조합으로 동작한다.
-
음향 모델 (Acoustic Model): 이 모델은 오디오 신호 그 자체를 분석하여 가장 작은 소리 단위인 '음소(phoneme)'로 분해하는 역할을 한다. 즉, 컴퓨터가 소리의 물리적 특성을 언어학적 기본 단위로 매핑하는, 진정한 의미의 '귀'에 해당한다.
-
언어 모델 (Language Model): 음향 모델이 분해한 음소들의 배열을 보고, 문법적, 문맥적 개연성을 따져 가장 가능성 높은 단어와 문장으로 조합한다. "아이스크림"이라는 소리를 "아이 스크림(I scream)"이 아닌 "아이스크림(ice cream)"으로 올바르게 인식하는 것이 바로 언어 모델의 역할이다.
대표적인 STT 모델: OpenAI의 Whisper
수많은 STT 모델 중, OpenAI의 Whisper는 뛰어난 성능으로 주목받고 있다. 68만 시간에 달하는 방대한 양의 다국어 데이터를 학습한 덕분에, 특정 억양, 배경 소음, 기술 용어 등에 매우 강건한(robust) 성능을 보여주기 때문이다. 이러한 강건함은 예측 불가능한 변수가 많은 실제 환경에서 높은 인식률을 보장하는 핵심 요소다.
Whisper는 내부적으로 인코더-디코더 트랜스포머(Encoder-Decoder Transformer) 아키텍처를 사용한다. 입력된 음성을 30초 단위로 잘라 '로그-멜 스펙트로그램'이라는 시각적 데이터로 변환한 뒤, 인코더가 이 스펙트로그램의 특징을 압축하여 수학적 표현으로 만든다. 그러면 디코더가 이 표현을 받아 가장 확률 높은 텍스트 순서로 번역해내는 구조다.
실제 구현 시 고려해야 할 점들
STT 기술을 실제 서비스에 적용하기 위해서는 모델의 원리를 아는 것 이상의 엔지니어링적 고민이 필요하다.
1. 한국어 STT의 특수성
영어 중심의 STT와 한국어 STT는 평가 방식과 처리 과정에서 중요한 차이가 있다.
-
평가 지표: 영어권에서는 주로 단어 오류율(WER, Word Error Rate)을 사용하지만, 한국어는 교착어 특성상 어절 단위의 오류보다 문자 단위의 오류가 더 직관적인 지표가 될 때가 많다. 그래서 문자 오류율(CER, Character Error Rate) 을 핵심 지표로 삼는 경우가 많다.
-
정규화(Normalization)의 중요성: 사용자가 체감하는 품질은 단순 텍스트 변환 정확도를 넘어선다. 예를 들어, "삼천오백만"이라는 음성을 "35,000,000"으로 변환해주는 숫자 읽기 정규화나, 문맥에 맞는 띄어쓰기처리가 매우 중요하다. 또한 "KB(킬로바이트)", "GHz(기가헤르츠)" 같은 단위나 외래어를 정확히 변환하기 위해 별도의 도메인 사전과 후처리 규칙을 적용하는 것이 필수적이다.
2. 스트리밍 vs. 배치: 실시간이냐 정확도냐
-
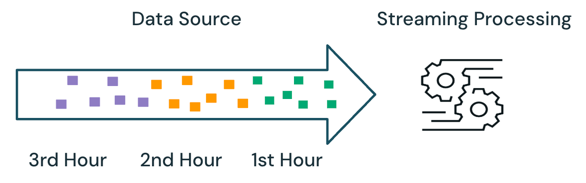
스트리밍 (Streaming): 웹소켓(WebSocket)이나 gRPC를 통해 실시간으로 음성 데이터를 처리하는 방식이다. 저지연성이 핵심이므로 실시간 자막이나 콜봇 서비스에 최적화되어 있다. 이를 구현하려면 20~40ms 단위로 오디오 프레임을 서버로 전송하고, 음성 감지(VAD, Voice Activity Detection) 기술로 발화의 끝을 판단하며, "정정" 전략을 통해 부분 결과를 안정화하는 등 복잡한 기술이 요구된다.
-
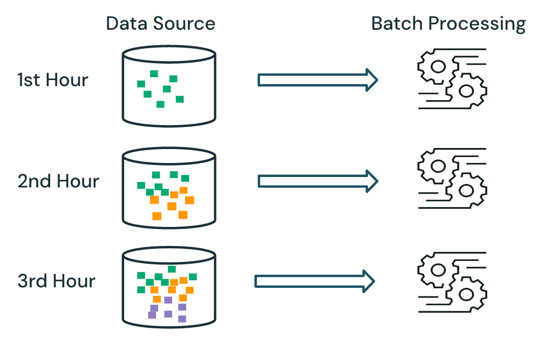
배치 (Batch): 녹음된 오디오 파일을 HTTP로 업로드하여 한 번에 처리하는 방식이다. 정확도를 우선하며, 서버 확장이나 재시도 로직 구현이 비교적 쉽다. 긴 오디오는 10~60초 단위의 청크(chunk)로 잘라 업로드하면 메모리나 타임아웃 위험을 줄일 수 있다. 실시간 미리보기가 필요 없는 '문항별 답변 녹음 후 제출' 같은 시나리오에서는 배치 방식이 훨씬 안정적이고 구현이 용이하다.
3. 실용적인 배포와 엔지니어링 체크리스트
-
오디오 포맷 변환: 브라우저의
MediaRecorderAPI는 보통audio/webm;codecs=opus포맷으로 오디오를 생성한다. 하지만 대부분의 STT 엔진은PCM s16le, 16kHz, mono포맷의 WAV 파일을 표준으로 사용한다. 따라서 서버단에서 ffmpeg 같은 도구를 이용해ffmpeg -i in.webm -ac 1 -ar 16000 out.wav와 같은 명령어로 포맷을 변환하는 과정이 필수적이다. -
품질 지표 모니터링: 단순히 CER/WER만 측정하는 것을 넘어, RTF(Real-Time Factor) (예: 1분 음성을 30초에 처리하면 RTF 0.5)와 **지연 시간(Latency)**을 꾸준히 모니터링하여 서비스 품질을 관리해야 한다.
-
도메인 튜닝: 서비스의 특성에 맞춰 인식률을 높이려면, 사용자 사전(custom vocabulary), 특정 단어의 인식 가중치를 높이는 핫워드(hotword) 기능, 그리고 후처리 규칙을 지속적으로 개선해야 한다. 사용자가 직접 오인식된 단어를 수정할 수 있는 UI를 제공하고 이 피드백을 다시 학습에 활용하는 루프를 구축하는 것이 이상적이다.
어떤 기술을 고를까(빠른 가이드)
-
최고 정확도, 배치: Whisper large/medium(한글 강함) + 구두점 복원 → 보고서/분석용.
-
저지연 실시간 자막/콜봇: Conformer-Transducer(RNNT) 계열(스트리밍 강점) + 핫워드.
-
온디바이스/경량: Vosk/Whisper-tiny-int8 + 사전 후처리.
-
클라우드 API: 빠른 시작·운영 편의. 한글 품질·가격·핫워드 지원 여부 비교.
최소 구현 레시피(당신의 현재 구조 기준)
-
클라이언트: MediaRecorder로 최대 3분, audio/webm;codecs=opus → 업로드.
-
서버(수신 직후):
-
ffmpeg -i in.webm -ac 1 -ar 16000 out.wav
-
Whisper/엔진 호출(배치) → 텍스트+타임스탬프
-
숫자/단위/고유명사 후처리, 금칙어 마스킹
-
-
추가 개선: 문항 길면 VAD로 15–30초 청크화, 실패 시 재시도/병렬 처리, 편집 UI 제공.
🔄 회고 및 인사이트
-
새로 알게 된 점: STT가 단순히 소리를 텍스트로 바꾸는 마법이 아니라, 음향 모델과 언어 모델의 협업 결과물임을 넘어, 실제 서비스에서는 오디오 포맷 변환(ffmpeg), 후처리 정규화, 전송 방식(스트리밍/배치) 설계 등 복잡한 엔지니어링 파이프라인이 뒷받침되어야 한다는 것을 배웠다. 특히 한국어의 경우 띄어쓰기나 숫자 변환 같은 후처리가 사용자 경험에 미치는 영향이 지대하다는 점을 깨달았다.
-
관점의 변화: 이전에는 STT API를 단순히 '가져다 쓰는 도구'로만 생각했다. 하지만 이제는 각 모델(Whisper, Conformer-Transducer 등)의 아키텍처적 장단점(배치 정확도 vs 스트리밍 저지연)을 비교하고, 내 서비스의 요구사항에 맞는 최적의 기술 스택과 처리 방식을 선택해야 하는 시스템 설계의 관점에서 바라보게 되었다.
-
추후 확장 아이디어: 범용 모델을 사용하는 것을 넘어, IT 직군 면접에 자주 등장하는 기술 용어나 약어(e.g., 'CI/CD', '쿠버네티스')의 인식률을 높이기 위해 모델을 파인튜닝(fine-tuning)하는 방안을 탐구해보고 싶다. 또한, 안정적인 실시간 상호작용을 위해 VAD와 부분 결과 안정화 로직을 포함한 스트리밍 아키텍처를 직접 구현해보는 것도 좋은 도전이 될 것이다.